
Why is the new processor faster at the same frequency?

We independently test the products and technologies that we recommend.

If you are ready to choose a processor yourself, we recommend using the profile section of the catalog. Here you can sort suitable models by various parameters, including clock speeds, generations (code names), cache memory size, etc.
Why does processor frequency hardly increase?
At the end of the 90s of the 20th century, the rate of growth of processor clock frequencies could only be rivaled by the rate of inflation. From tens of MHz, processors quickly moved to hundreds, and then to GHz. This growth resulted in an increase in the number of operations performed per second, that is, it directly increased flow Rate. But already in the middle of the 2000s, this race stalled. The conventional Pentium 4 of tech years had about 3 GHz, and today many Core i5 have comparable frequencies.
There has been no active growth for more than 10 years. Why is that? Primarily due to heat dissipation (TDP). To further increase the frequency of the chips, it is necessary to increase the operating voltage. It directly affects the amount of heat generated by the processor - its numerous transistors.
So, in order to double the clock frequency, you will have to increase the heat dissipation by approximately 8 times. In such a scenario, you definitely cannot do without a cool cooling system, probably water. Due to the fact that the growth of Hertz processors came up against TDP indicators, engineers had to change their approaches to work.

Frequencies can also be increased by improving technical processes. The logic here is this: the smaller the components of the chip, the faster the signals will travel and the higher the operating speed. The transition to thinner technical processes occurs non-stop: in 2024 we have already reached 4 nm, and 10 years ago 22 nm was a revelation.
True, in practice, a more subtle technical process does not provide a noticeable increase in frequencies. It’s just that while nanometers (nm) are decreasing, the physical dimensions of the crystals are growing, the number of cores is increasing, which means that signals travel almost the same distances as before.
It turns out that until a new technological breakthrough in processor design we should not expect an active increase in frequencies. This means that the flow Rate increase will occur due to other optimization methods.













What makes processors faster today?
Today, optimization of processor microarchitecture, which is aimed at:
- computing cores;
- memory subsystems (various types of cache and intermediate clipboards);
- data buses.
The main work of Intel and AMD engineers is often aimed at increasing the Instruction Per Clock (IPC) indicator - the number of instructions executed per clock cycle. If you can raise the IPC, then the processor does more calculations and runs faster than its predecessors. Chips are extremely rarely made from scratch: usually a new generation is the result of eliminating existing bottlenecks, refining existing blocks, software optimization, etc.
An indirect method of increasing the efficiency of chips is to reduce the heat dissipation for each computational operation. But this is not so much a flow Rate factor as a way to increase the stability of clock frequencies under high or extreme loads.
Let's take a closer look at the main ways to speed up modern processors.
Optimization of computing cores
Modern chips adhere to pipeline processing, that is, they break incoming instructions for execution into many simpler operations. This is reminiscent of a typical assembly line in a factory, where each worker does only one thing. Processes do not run sequentially, but in parallel, which increases overall productivity.
True, qualitative changes lead to more complex processors. So, each operation in the instruction has its own block. Plus , in new generations of chips, additional elements appear that are designed to speed up the pipeline, increase its throughput, reduce downtime(even more crushing incoming instructions into small operations), etc.
Here are just some blocks and examples of their modernization:
- Branch Predictors - branch predictors. They predict in advance the execution of certain instructions from running programs. Improvements here reduce the number of incorrect predictions, which improves overall flow Rate.
- Decoders - decoders. Transform complex commands from programs into the simplest micro-operations. More decoders are added to the new cores, thanks to which the processor is ready to execute more instructions per unit of time (subject to upgrading other blocks).
- Schedulers - execution schedulers. These are blocks that queue up instructions. The scheduler upgrade ensures that the computing cores work without downtime.
- Register File - register file. An element that stores command codes while it is being executed. Modernization may concern storage expansion, which in turn will increase the throughput of operations performed.
- Execution Ports - execution ports. These are the same blocks that implement individual stages of instructions. An example of an improvement is an increase in the number of such ports. As a result, more operations are carried out simultaneously and the speed of execution of instructions increases.
- Load/Store - saving/loading block. It is responsible for saving and loading data from memory. Improving this block increases the efficiency of interaction between the processor and memory.
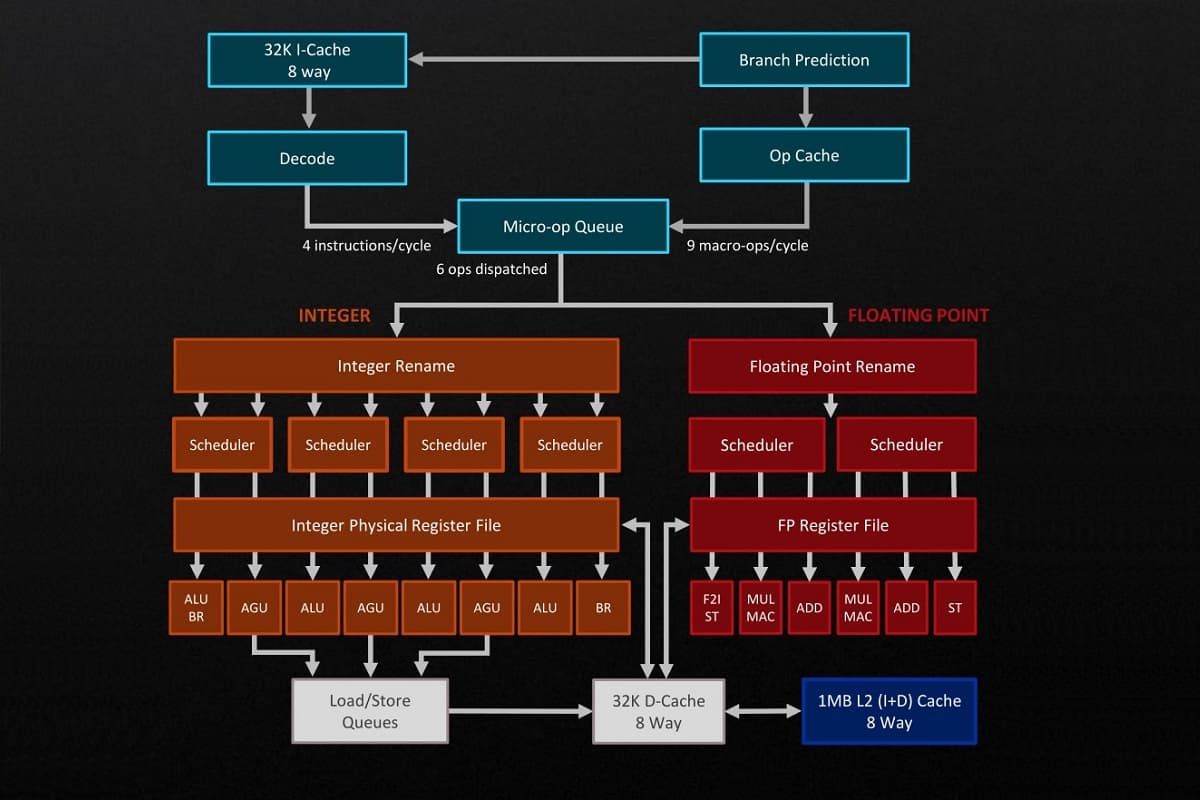
The structure of computing cores is complex, and the number of blocks is increasing. But this means that the possibilities for further increasing flow Rate have certainly not been exhausted.
Memory subsystem improvement
The number of instructions executed by the processor per clock cycle is affected not only by the efficiency of the computational units, but also by the operation of the memory subsystem. Modern chips necessarily have several types of cache and intermediate buffers. Each of the levels from L0 to L3 is designed to speed up work within its area of responsibility - a specific computational stage.
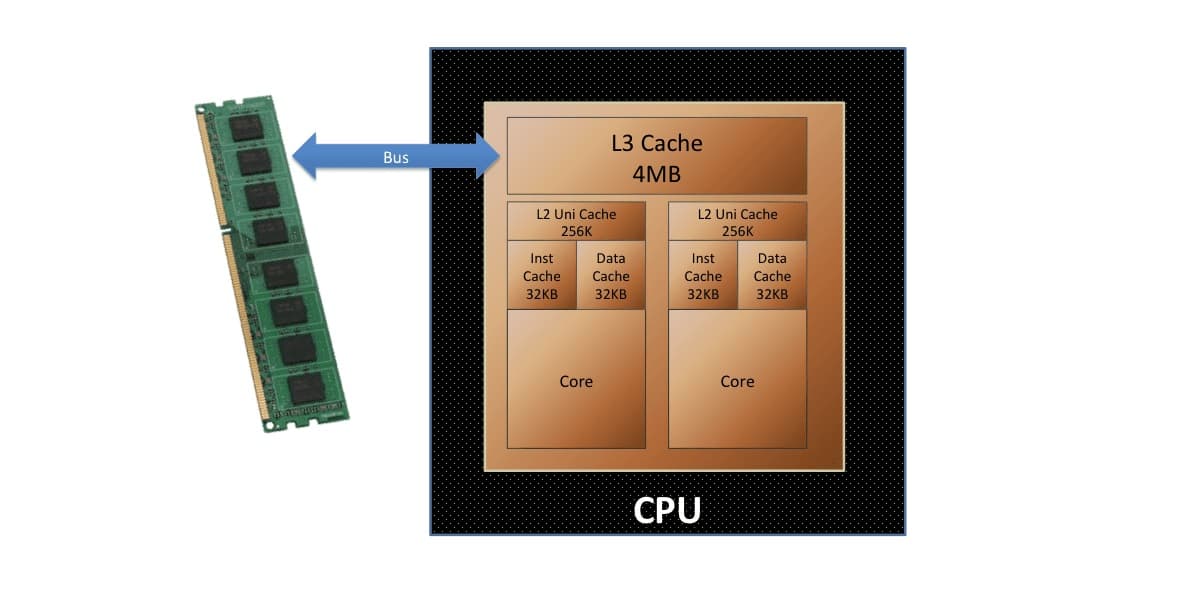
Multi-level cache organization in processors is not used by chance. As memory increases in size, it invariably becomes slower. Therefore, the first level cache is calculated in kilobytes, but guarantees maximum flow Rate. At the same time, the increase in L3 cache volume (in new processors they sometimes exceed 100 MB) is also justified, because it increases the amount of data that can be stored and quickly accessed.
So, the most obvious methods of accelerating the processor using the memory subsystem are to increase the number and bandwidth of the cache. But modernization is not limited to this, and may also include:
- Changes in cache organization. Today, the so-called non-inclusive option is increasingly used. Data is not duplicated at all cache levels, but is tracked and selected based on predictions. As a result, L0 contains the most necessary things right now, and L3 displaces what is unnecessary to save space.
- Optimization of the number of channels. Data in the cache is often accessed through different “chains”. The more channels, the higher the probability of finding what you need in the memory subsystem. But multichannel can also complicate access to the cache, which will negatively impact flow Rate. Accordingly, you need to look for the optimal balance.
- Increase in additional (intermediate) buffers.
And to increase the computing potential and speed of the computer as a whole, new processors are equipped with improved controllers - compatible with the latest generations of RAM, including DDR5 with high frequencies.










Data bus acceleration
In multi-core processors, the overall flow Rate is affected by the speed of data transfer between the processing cores and other components of the chip. Accordingly, the tire used is not the least important.
Each manufacturer uses its own proprietary developments:
- Intel has a Ring Bus ;
- AMD has an Infinity Fabric interconnect bus.
As a rule, tire improvements occur once every few generations. This is enough to cover the flow Rate needs caused by the increase in the number and computing potential of cores.
What "speeds up" Intel processors?
Architectural improvements and their impact on flow Rate are clearly demonstrated using actual examples. Intel does not have big jumps in clock speeds, but Instruction Per Clock indicators are still growing. Yes, not in every generation, but the trend is obvious.

In 2021, the company introduced chips codenamed Rocket Lake. These 11th generation desktop processors have become 10–12% faster than their Comet Lake predecessors. And all thanks to these architectural upgrades:
- The Decoders block has been expanded: it has become possible to execute 5 instructions, instead of 4;
- the number of execution ports has been increased to 10 (previously there were 8);
- the Load/Store block has been modernized;
- The volumes of intermediate buffers, L2 and L1 caches have increased;
- The first level cache has been accelerated.
A year later, Alder Lake and Raptor Lake processors were released - the 12th and 13th generations, respectively. Compared to their predecessor, the flow Rate increase for these models was 15–20%. The following architectural changes have occurred here:
- The decoder has been improved again - it is capable of executing 6 instructions per clock cycle;
- the number of Execution Ports has been increased to 12;
- added support for DDR5 RAM;
- caches of all levels, as well as intermediate buffers, have been enlarged and accelerated.
Raptor Lake has few changes compared to Alder Lake. Thus, in the 13th generation of chips, the number of energy-efficient Gracemont cores has increased and there is more L2 and L1 cache. IPC indicators remained approximately at the same level.
The Raptor Lake Refresh generation debuted in the fall of 2023 and was actually a cosmetic update to the Raptor Lake chips. There are no architectural changes here, only the number of energy-efficient cores has increased and some software improvements have been introduced, including dispatch policy. The upgrade resulted in an increase in clock frequencies by 100 – 200 MHz. So, there is a direct increase in flow Rate. It stands out somewhat from current trends: it can be considered an exception that confirms the rule.
The main differences in the microarchitecture of current Intel processors (without the 14th generation) are summarized in the table:
| Code name | Rocket Lake | Alder Lake | Raptor Lake |
|---|---|---|---|
| Generation | eleven | 12 | 13 |
| Technical process | 14 nm | 10 nm | 10 nm |
| Number of instructions in work | 5 | 6 | 6 |
| Number of execution ports | 10 | 12 | 12 |
| Increase L1 cache | + (by 150%) |
+ | - |
| Increase L2 cache | + (by 250%) |
+ | + (up to 2 MB per core) |
| Increase L3 cache | - | + | + (up to 4 MB per cluster) |
| Cache acceleration | + (for L1) |
+ (for levels) |
- |
| Other innovations | Load/Store block upgrade, other buffers increased | DDR5 RAM support, other buffers increased | more energy-efficient Gracemont cores, DDR5-5600 support |
| Performance increase compared to predecessors with the same frequency, in % | 10 – 12 | 15 – 20 | - |




What "speeds up" AMD processors?
The direct impact of optimization of processor microarchitecture on operating speed is clearly visible in AMD processors. Let's trace the changes, starting with Zen3 chips.
AMD processors codenamed Cezanne were released at the end of 2020. This is the fifth generation, which compared to Zen2 has become 20% faster and has caught up with Intel in terms of flow Rate per thread (having lagged behind for many years before). And all thanks to these improvements:
- the Branch Predictors block has been improved;
- the number of execution ports is increased to 8;
- Schedulers blocks have been optimized - there are fewer of them, but the flow Rate has doubled;
- improved Load/Store block;
- The volume of the third level cache and intermediate buffers has been increased.
In mid-2022, the 6th generation of AMD processors was released - Zen4 Raphael. There was a transition to the 5 nm process technology, plus various innovations were introduced at the microarchitecture level, due to which IPC increased by 13%. What's better:
- new upgrade of the transition predictor;
- controllers supporting DDR5 RAM;
- L2 cache has been doubled - up to 1 MB per core instead of 0.5 MB;
- the Load/Store block has been modernized;
- The register file and intermediate buffers have been enlarged.
At the beginning of 2024 , Zen4 Phoenix hybrid desktop processors were introduced. The highlight of this generation is the emergence of compact Zen 4c computing cores. They became smaller, but retained the productivity (IPC) of their Raphael predecessors, which also indicates increased energy efficiency. Compact cores can be combined with regular ones, which in the future will add variability to manufacturers.
Note that in the summer of 2024, a new generation of AMD processors - Granite Ridge (Zen5) - will debut. At the time of writing, they have not yet gone on sale, but they are claimed to have a flow Rate increase (according to Instruction Per Clock) of 16%.
The main differences in the microarchitectures of current AMD processors (without Zen5) are presented in the table:
| Code name | Zen3 Cezanne | AMD Zen4 Raphael | Zen4 Phoenix |
|---|---|---|---|
| Generation | 6 | 7 | 8 |
| Technical process | 7 nm | 5 nm | 4 nm |
| Improving transition predictors | + | + | no data |
| Number of execution ports | 8 | 8 | 8 |
| Increase L1 cache | - | - | - |
| Increase L2 cache | - | + (up to 1 MB per core) |
- |
| Increase L3 cache | + (up to 16 MB for 8 cores) |
- | - |
| Cache acceleration | - | - | - |
| Other innovations | Load/Store block upgrade, other buffers increased, monolithic L3 cache used | support for DDR5 RAM, larger register file and other buffers, Load/Store block upgrade | reduction in the size of computing cores - the emergence of Zen 4c |
| Performance increase compared to predecessors with the same frequency, in % | 20 | 13 | - |
Conclusions and recommendations
When choosing a processor, most buyers, out of habit, look only at the frequencies and number of cores, ignoring other parameters. In current realities, the main increase in flow Rate lies in the details - in the optimization of the processor microarchitecture. Therefore, if possible, before purchasing, you should pay attention to innovations in the blocks of computing cores, changes in the size of the cache at different levels, and even updates to data transfer buses.
The main increase in IPC—the number of instructions executed per clock cycle—usually comes from obvious improvements in the microarchitecture. Although in practice a lot depends on the tasks being solved and specific programs. One software works faster by upgrading the computing units, and the other by increasing and accelerating the memory subsystem.







Articles, reviews, useful tips
All materials




